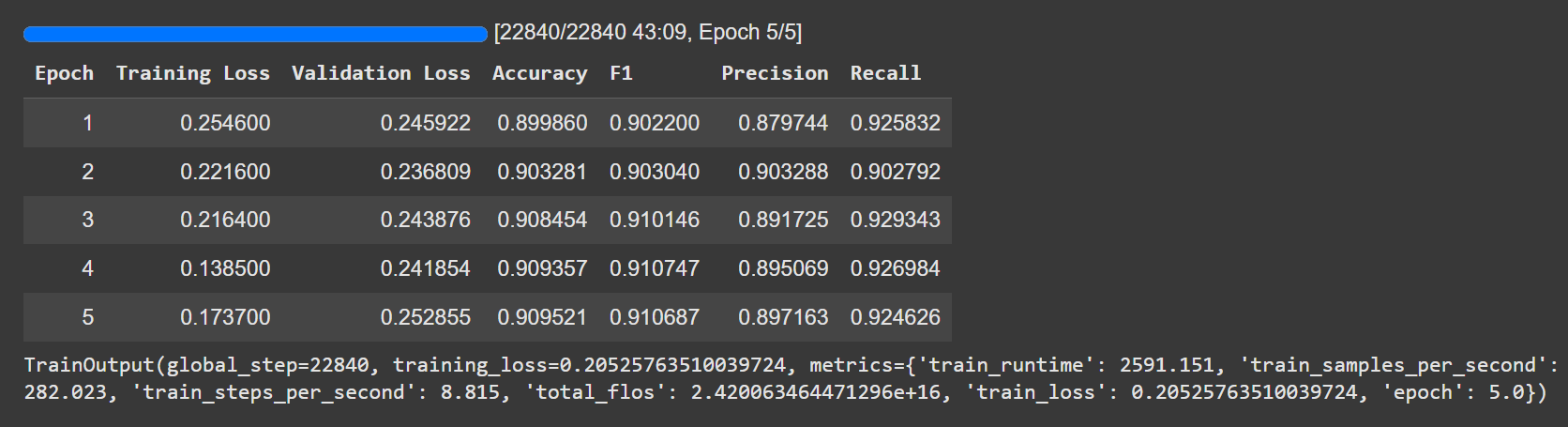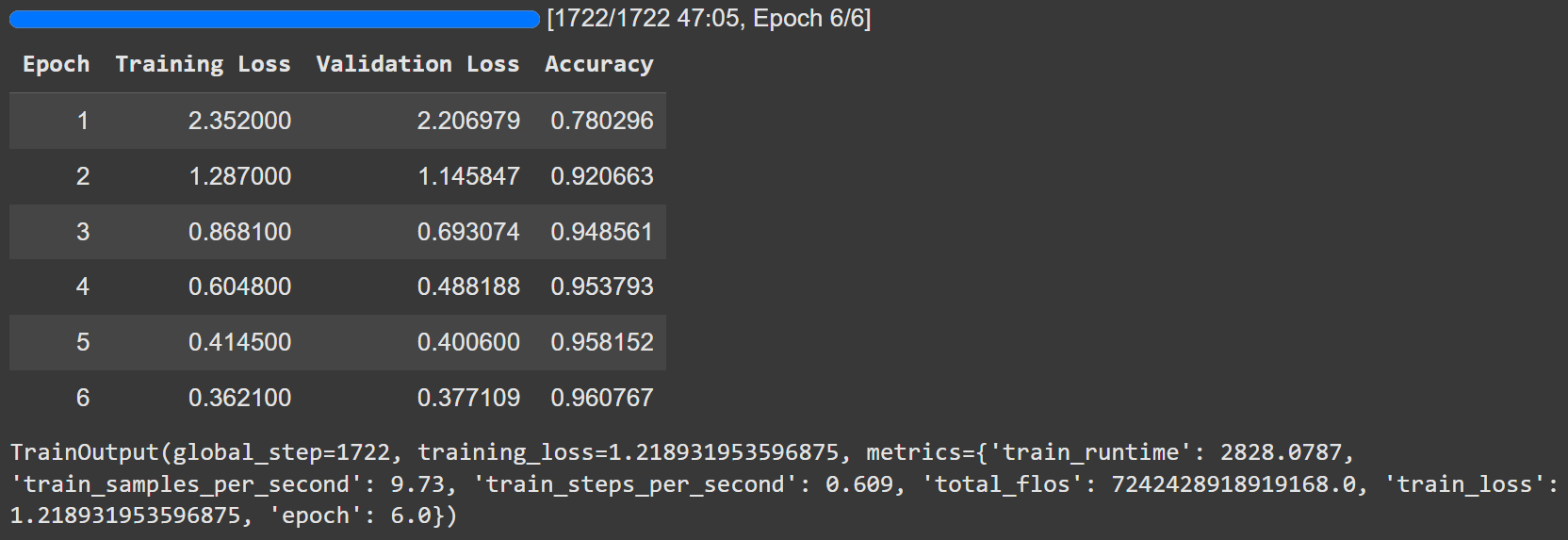
An n-gram is simply a contiguous sequence of N items from a given text.
Unigram (1-gram): one word at a time
Example: "I love NLP" → ["I", "love", "NLP"]
Bigram (2-gram): two-word pairs
Example: "I love NLP" → ["I love", "love NLP"]
Trigram (3-gram): three-word sequences
Example: "I love NLP" → ["I love NLP"]
NLP based Resume Screening and
Job recommendation system
Developed by byte brains
Developers
Mahnoor Ishfaq
M. Umar Farooq
Muntaha Javed
PROCESSING
.
.
.